A Saturday-night game of Catan is social, noisy, and fun. There are four players, hidden hands, dice, and, most importantly, talking. People haggle, bluff, complain about their dice rolls, and refuse a perfectly fair trade out of spite. So what happens when we ask machines to play in that kind of world? The social side is the part most algorithm papers tend to skip.

In this post, we will discuss the PyCatan project, an open-source environment where reinforcement-learning agents learn to build, trade, and win at Catan, while also speaking in character as AI personas that argue with one another. The code is available on GitHub [1]. One question we ask is whether an agent can learn to play well from scratch. Another is how to make an AI say something genuinely in character about a game position without letting it hallucinate the position itself. We start with the second question, because that is where Catan becomes different from many other games.
Two sides of the problem

When Miss Minutes (yes, the clock from the Loki series) says “how ’bout a wheat for a brick, partner?” it is easy to imagine a large language model reading the board and deciding what to say. That is exactly the architecture we did not build. Language models are excellent at tone and unreliable at facts. If we hand the raw game state to a chat model and ask it to comment, it will cheerfully tell you that a player has the longest road when they do not, because sounding right and being right are different objectives.
So we split the problem in two: one part knows what is true, and the other knows how to say it. The factual part is plain, deterministic Python; the language model only handles the wording.
The sentence machine
The factual layer lives in a function called create_message, and it is intentionally plain. Given the state vector and the action a player just took, it produces a paragraph of flat English: who the active player is, what they proposed, what was actually executed, whether a trade was accepted and by whom, how the shortest street-distance between every pair of players changed, whether the ‘longest road’ changed hands, and how each player’s score moved.
A single turn comes out of the factual layer looking like this:
The active player is HAL 9000. The original proposed action was: HAL 9000 proposes a trade with another player. Card to give: ore, card to receive: wheat. The proposed trade was rejected by all players… HAL 9000 constructs a road at edge 38. HAL 9000’s street length has increased to 2, but this player still does not have the longest street. Before executing the action, the scores were: HAL 9000 has 3 victory points…
Every clause in there is deterministic. The distance deltas come from an actual shortest-path calculation on the board graph; the longest-road logic walks through six explicit cases (did they have it and keep it, gain it, lose it, extend it without having it, and so on).
There is an important distinction between the proposed trade and the action that was actually executed. In Catan, you can offer a trade and have everyone reject it. In PyCatan, after five trade proposals are rejected, the player must take another action. The sentence machine reports both what you wanted and what you got, which gives the narrator something to be smug or disappointed about.
Giving the machine a voice (four of them)
Only now does a language model enter, and it enters under strict constraints. Each player gets a persona — by default Miss Minutes, HAL 9000, Marvin the Paranoid Android, and C-3PO — with a few hundred words of guidance covering voice, behaviour at the table, tone, and example lines. At every turn, we build a prompt from three parts: the persona as a system prompt, the factual sentence from the machine above, and the player’s own recent comment history so the character does not contradict itself or repeat stock phrases. That prompt is sent to a small chat model (gpt-4o-mini) at temperature 0.8, capped at about seventy tokens, with a deliberately randomised instruction — sometimes “one short sentence”, sometimes “a word or a phrase” — so the rhythm does not get monotonous.
The language model never sees the board. It sees an English summary. That separation means that HAL can be eerily calm about placing the robber and C-3PO can fret about the odds, but neither of them can invent a victory point, because the models are only asked to react to the board state.
The other half: an agent that actually plays
The narration is a layer on top of a game that the agents are playing for real, and the players doing the building and trading are not language models at all. They are small neural networks trained with reinforcement learning.
Here it helps to know what the board looks like to the machine (see the figure below). A position is flattened into three vectors: the 54 nodes (where villages and towns can sit), the 72 edges (roads), and the 20 numbers describing every player’s hand of resources (five tradeable resources for each of the four players). The two board vectors are categorical — a node is empty, or it is somebody’s village, or somebody’s town — so they go through small embedding layers, the way you would embed words; the hand vector is just numbers, lightly normalised. These feed a modest shared trunk (two dense layers, 128 then 64 units) which splits into two heads. One head, the ‘policy’, produces a probability for each of 241 possible actions. The other, the ‘value’, produces a single number: an estimate of how likely the active player is to win from here.
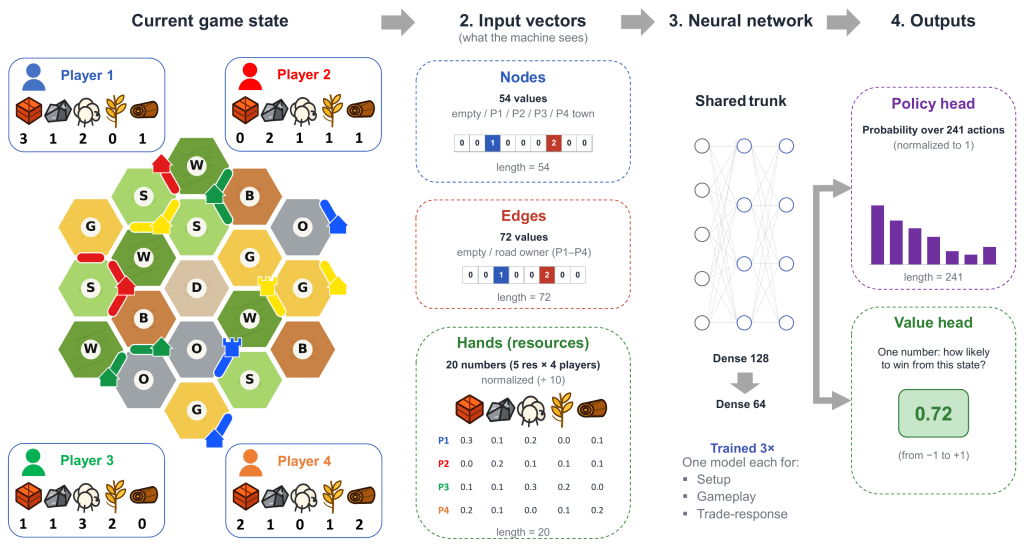
How a Catan position reaches the network. The current game state becomes three input vectors — 54 nodes and 72 edges (categorical, so they are embedded) and 20 hand values (numeric, normalised by 10) — which feed a shared trunk that splits into a ‘policy’ head (a probability over all 241 actions) and a ‘value’ head (a single estimate of how likely the active player is to win from here).
That single network is the whole brain, and it raises an obvious problem. Of those 241 actions, the vast majority are illegal at any given moment — you cannot build a road where you have no road to extend from, cannot trade cards you do not hold. How do we stop the network from confidently choosing an impossible move?
The answer is an action mask, and it is handled inside the network rather than patched on afterward. Alongside the board, the model receives a vector of ones and zeros marking which actions are legal right now. Just before the final softmax, every illegal action has a large negative number added to its score (−10⁹, which is ‘minus infinity’ for all practical purposes). After the softmax, those actions hold essentially zero probability. The model is free to prefer whatever it likes among the legal moves, and structurally forbidden from leaking probability onto the illegal ones.
Three jobs, one design
We identify three distinct moments in the game: the opening setup placement, ordinary gameplay, and the narrow decision of whether to accept a trade someone offers you. This is implemented in three distinct models (each with their own training). At the table, the player simply looks at which kind of decision it faces and asks the matching specialized model.
Why split them? Because these are genuinely different skills. Where you place your first two settlements is a long-horizon judgement about the whole game to come; whether to accept a brick-for-ore trade three turns from victory is a sharp, local calculation. Asking one network to be excellent at both, in one set of weights, is asking a lot. Specialising is cheaper than it sounds, since they share an architecture, and it lets each model’s value head learn what ‘winning from here’ means in its own phase.
Learning without starting from zero
Now, how do these networks actually get good? If we initialised them randomly and let them play, the early games would be close to noise — a random legal player, as we will see, is catastrophically bad — and reinforcement learning from pure noise is slow and miserable.
So we bootstrap. Before any reinforcement learning happens, we generate a large pile of games played by a hand-written ‘heuristic’ player — a rules-of-thumb bot that is decent but not brilliant — and we train the networks to imitate it. This is ordinary supervised learning: copy the heuristic’s move distribution, and learn a value head from how those games actually turned out. It will not produce a champion. By construction, an imitator can only approach the thing it imitates, and usually lands a little below it. But it gives reinforcement learning a sane place to start, instead of from chaos.
Then the real training utilizes PPO (Proximal Policy Optimization). The idea is cautious self-improvement: let the current policy play, see which actions did better than the value head expected (the ‘advantage’), and nudge the policy toward those — but clip how far it is allowed to move in any one update, so a few lucky games cannot disrupt the whole strategy. We add a small bonus for keeping the policy’s choices varied (an entropy term, so it keeps exploring rather than collapsing onto one opening), and we stop a training round early if the policy has drifted too far from where it started, backing off the learning rate when that happens. The advantages are normalised per round and clipped, because the difference between a clean training signal and a noisy one is mostly bookkeeping like this.
This is fairly textbook PPO. We found that the masking, the per-phase models, and the bootstrap are required to make it actually train on a game this irregular.
What do we expect to find?
To evaluate performance we run a tournament where a random player, a heuristic player, an ‘imitation trained player’ and a PPO optimized player compete against eachother. Note that we rotate the seating each game to wash out any position bias (going first does have an advantage in Catan). We score the games in the tournament by rank — 10 points to the winner of a game, 5 for second, 2 for third, 0 for last — which comes to 17 points shared out per game. At the end of the tournament we compare average score. So:
- A player choosing random legal moves should be near zero. It will essentially never win.
- The imitation-learning player should land near, but slightly below, the heuristic it copied — that is what imitation means.
- If reinforcement learning is doing its job, the RL player should score clearly above the heuristic player.
And that is, more or less, what the 400-game tournament shows:
| Player | Avg points | Std |
|---|---|---|
| Random | 0.12 | 0.07 |
| Heuristic | 4.19 | 0.80 |
| Imitation learning | 3.24 | 0.77 |
| Reinforcement learning | 5.47 | 0.20 |
The random player is almost exactly zero. The imitator lands below the heuristic, as it must. And the RL player clears 5.47 — well above the imitation trained player. Note also its standard deviation: 0.20, far tighter than the others. It does not just win more; it wins more consistently, which is often the better sign that a policy has found something real rather than getting lucky.
A note on the plumbing
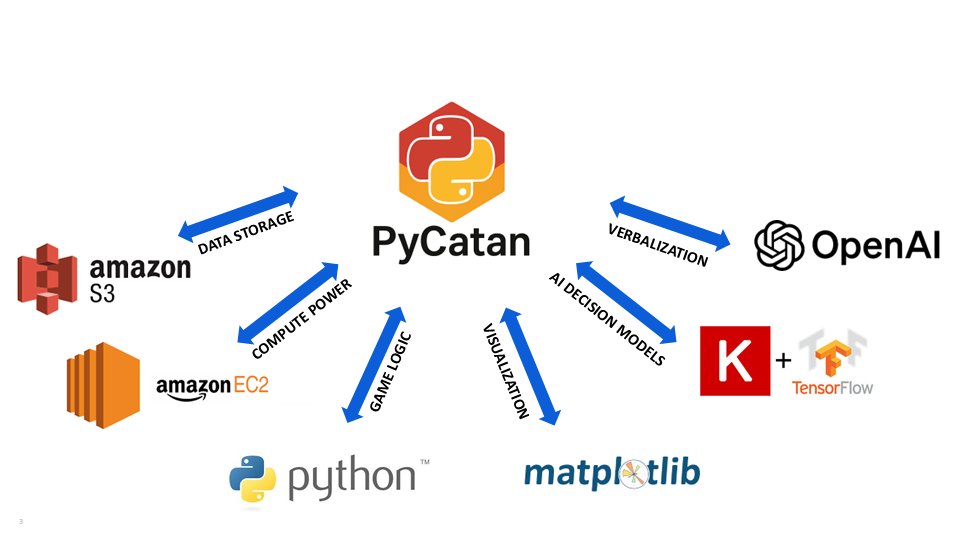
The PyCatan software ecosystem: Python game logic, Keras and TensorFlow for the decision models, OpenAI for verbalization, matplotlib for visualization, and AWS S3 and EC2 for storage and compute.
Generating enough self-play games to train on is intensive, and the data generation is built to run many workers in parallel, with models and datasets checkpointed to S3 and training pushed onto EC2 instances. This is not specialized infrastructure, but it is the difference between an idea and an experiment you can actually run more than once. (The repository and the tutorials are there for exactly that [1].)
So, what did the sheep teach us?
We can create an AI that talks in character about a game and an AI that plays the game well. They are best built as separate systems with a clean interface between them: a layer that knows the facts, and a layer that knows how to talk about it.
The RL player in PyCatan learned to play a four-way game of scarcity and negotiation well enough to beat its teacher — but it learned this in a version of Catan where the actual trade negotiation is fairly mechanical (accept or reject), and where the talking and the playing never touch. The personas comment on the game; they do not yet bargain their way through it. What would happen if the language and the strategy were not two halves bolted together but one loop, where persuading another player were itself a learned action? I do not know, and I am not sure the current setup could tell us. But it is the question this project leaves me with, and possibly it is the more interesting game to teach a machine next.
You can explore the code, run your own tournaments, and watch the four of them bicker through a full match on GitHub [1]. Just don’t be surprised if the AI starts making better trades than you do — it has, after all, had rather a lot of practice.
References
[1] PyCatan — source code, tutorials, and gameplay video. https://github.com/robhendrik/PyCatan
[2] Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press.
[3] Schulman, J. et al. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.
[4] Silver, D. et al. (2017). Mastering the game of Go without human knowledge. Nature.

Plaats een reactie